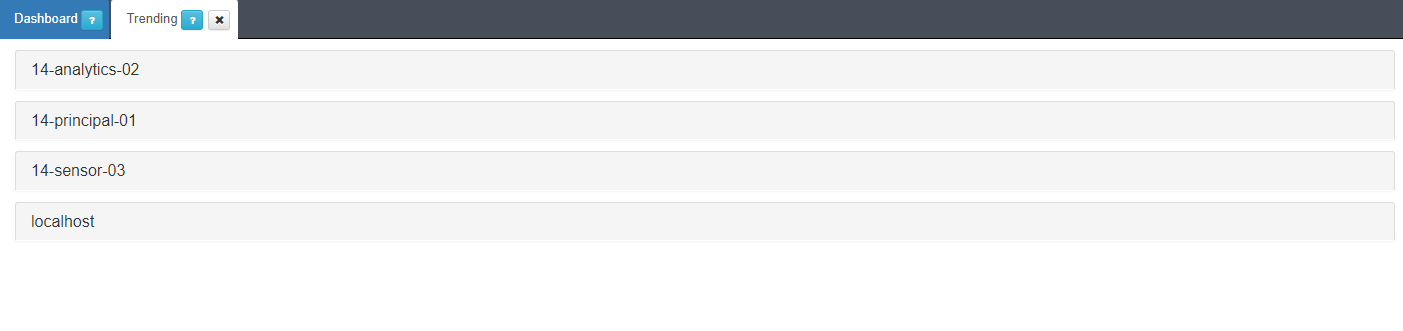
3.1.11.3. Trending
To check OpenNAC Enterprise performance and its trend you have to go to Status -> Trending.
In this section, we can find information on the current status of the services and resources of the infrastructure components. This information is displayed in graph format. The main idea to keep in mind in this section is that the most important aspect of it is their trends. We will be able to locate anomalies when in any of these graphs we find values that come out of their expected value.
In case we have a distributed deployment with many different nodes, per node trending, performance and graphs are also available.
Note
It is important to have the collectd service running. If you have multiple nodes deployed and you do not see its trending, please verify your collectd configuration on /etc/collect.d/network.conf
To configure the /etc/collect.d/network.conf, see the following examples:
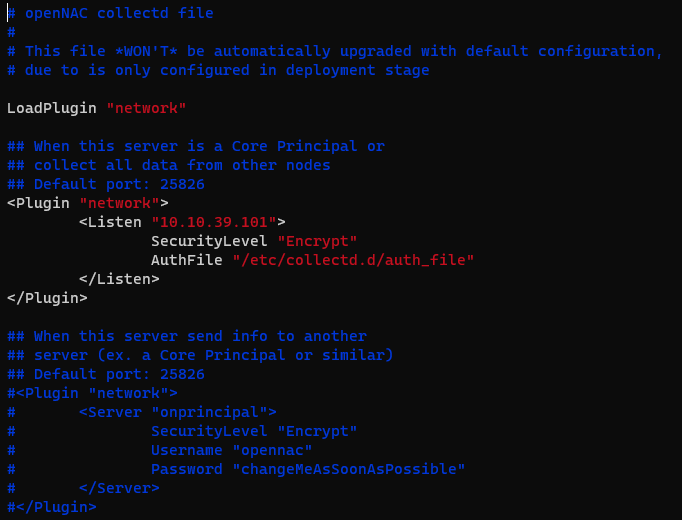
On the Principal node, the configuration on /etc/collect.d/network.conf should look like this:
# openNAC collectd file # # This file *WON'T* be automatically upgraded with default configuration, # due to is only configured in deployment stage LoadPlugin "network" ## When this server is a Core Principal or ## collect all data from other nodes ## Default port: 25826 <Plugin "network"> <Listen "<onprincipal_IP>"> SecurityLevel "Encrypt" AuthFile "/etc/collectd.d/auth_file" </Listen> </Plugin> ## When this server send info to another ## server (ex. a Core Principal or similar) ## Default port: 25826 #<Plugin "network"> # <Server "onprincipal"> # SecurityLevel "Encrypt" # Username "opennac" # Password "changeMeAsSoonAsPossible" # </Server> #</Plugin>
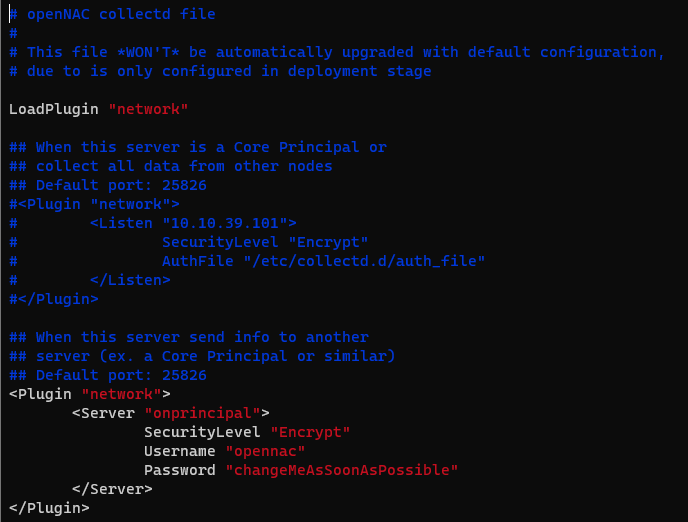
On the other nodes, the configuration on /etc/collect.d/network.conf should look like this:
# openNAC collectd file # # This file *WON'T* be automatically upgraded with default configuration, # due to is only configured in deployment stage LoadPlugin "network" ## When this server is a Core Principal or ## collect all data from other nodes ## Default port: 25826 #<Plugin "network"> # <Listen "10.10.39.101"> # SecurityLevel "Encrypt" # AuthFile "/etc/collectd.d/auth_file" # </Listen> #</Plugin> ## When this server send info to another ## server (ex. a Core Principal or similar) ## Default port: 25826 <Plugin "network"> <Server "onprincipal"> SecurityLevel "Encrypt" Username "opennac" Password "changeMeAsSoonAsPossible" </Server> </Plugin>
All the information is stored in DDR Files. This increases graphs calculation and system response.
Back to the Administration portal, if we unfold the tabs we can see the different tabs with time Ranges available, allowing us to select fom 1H (1 hour tim range) to 1Y (1 year time range). If we select a shorter range we will be able to see more details. We also can enlarge the graph by clicking on the eye icon.

The available sections are:

Cpu: Graphs regarding CPU usage.
OpenNAC: Graphs regarding OpenNAC Enterprise services.
Disk: Graphs regarding OpenNAC Enterprise disks.
Interface: Graphs regarding interfaces.
Load: Graphs regarding system components load.
Memory: Graphs regarding memory use.
Mysql: Graphs regarding database components.
Redis: Graphs regarding Redis component.
Other: Graphs regarding other components such as the Active Directory sub-component.
Conntrack: Graphs regarding the Conntrack component.
On the other nodes we may have less sections:
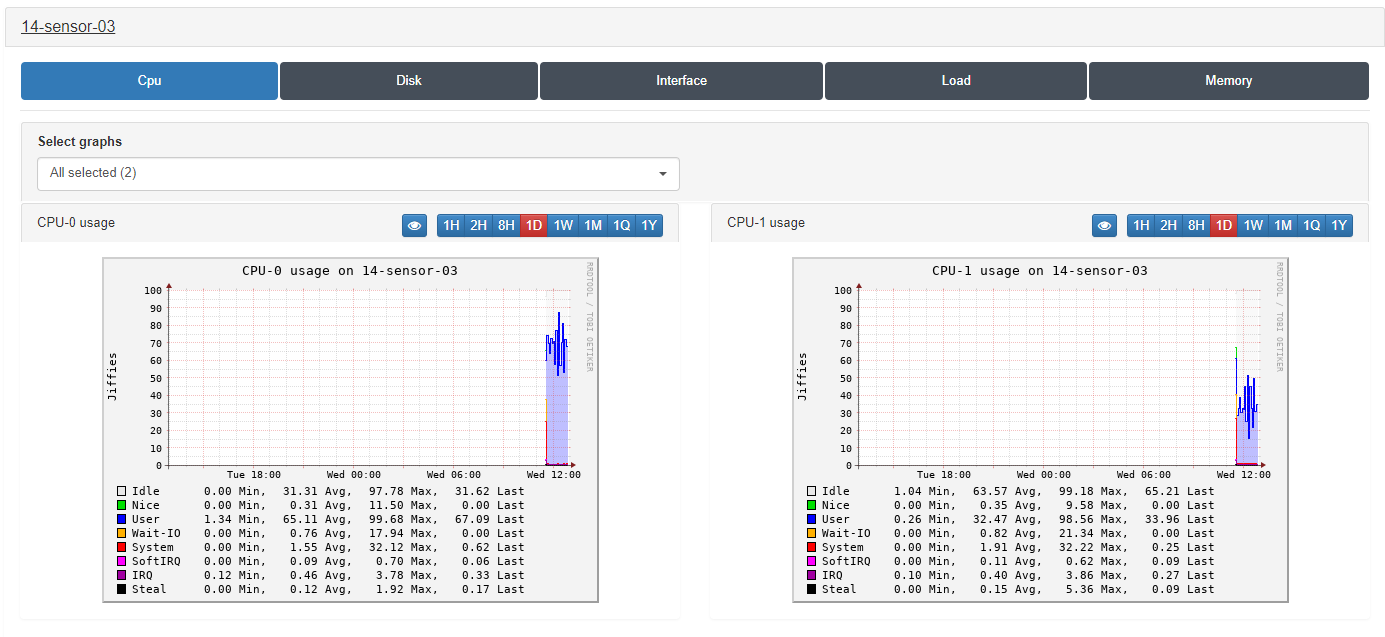
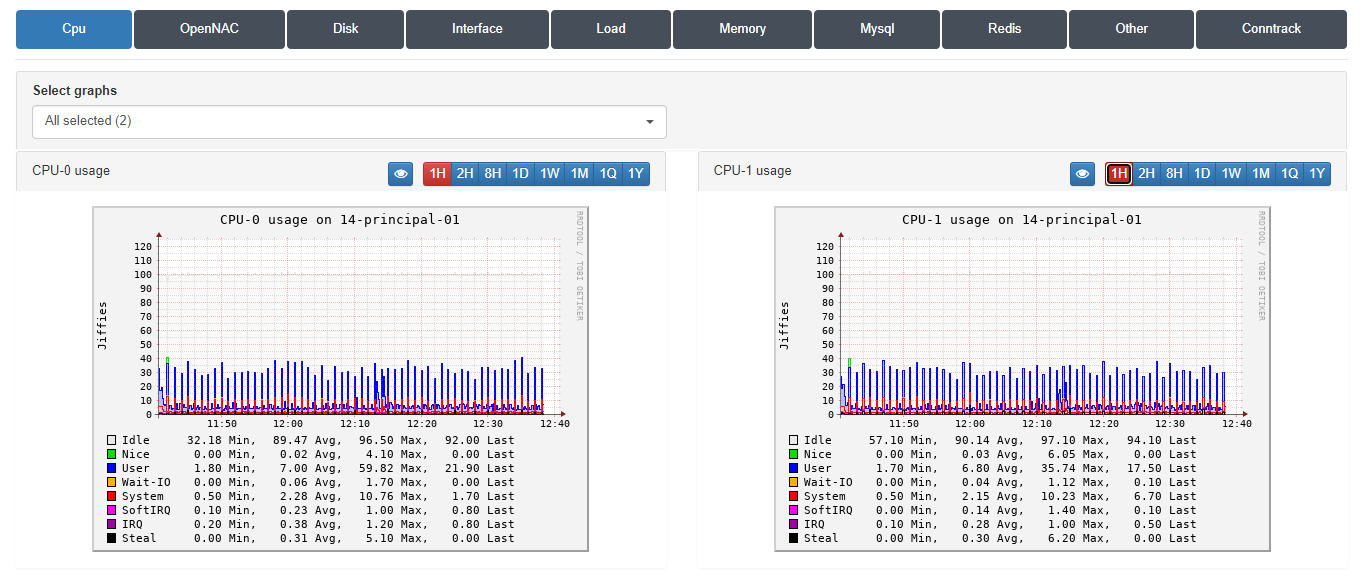
3.1.11.3.1. Trending CPU
From this window, we can see in graph format the use of each of the CPUs that we have in our node. We will be able to observe the measured use in Jiffies of the last days and which service has used it the most (User, Idle, System, etc.), defining the total minutes, its average, its maximum and last time used.
We can find more information about the values that are shown in this CPU graph in the CentOS or RedHat documentations, since they are standard Linux values.
3.1.11.3.2. Trending OpenNAC
In this section, we can see OpenNAC Enterprise engine’s information. There is a total of 12 charts.
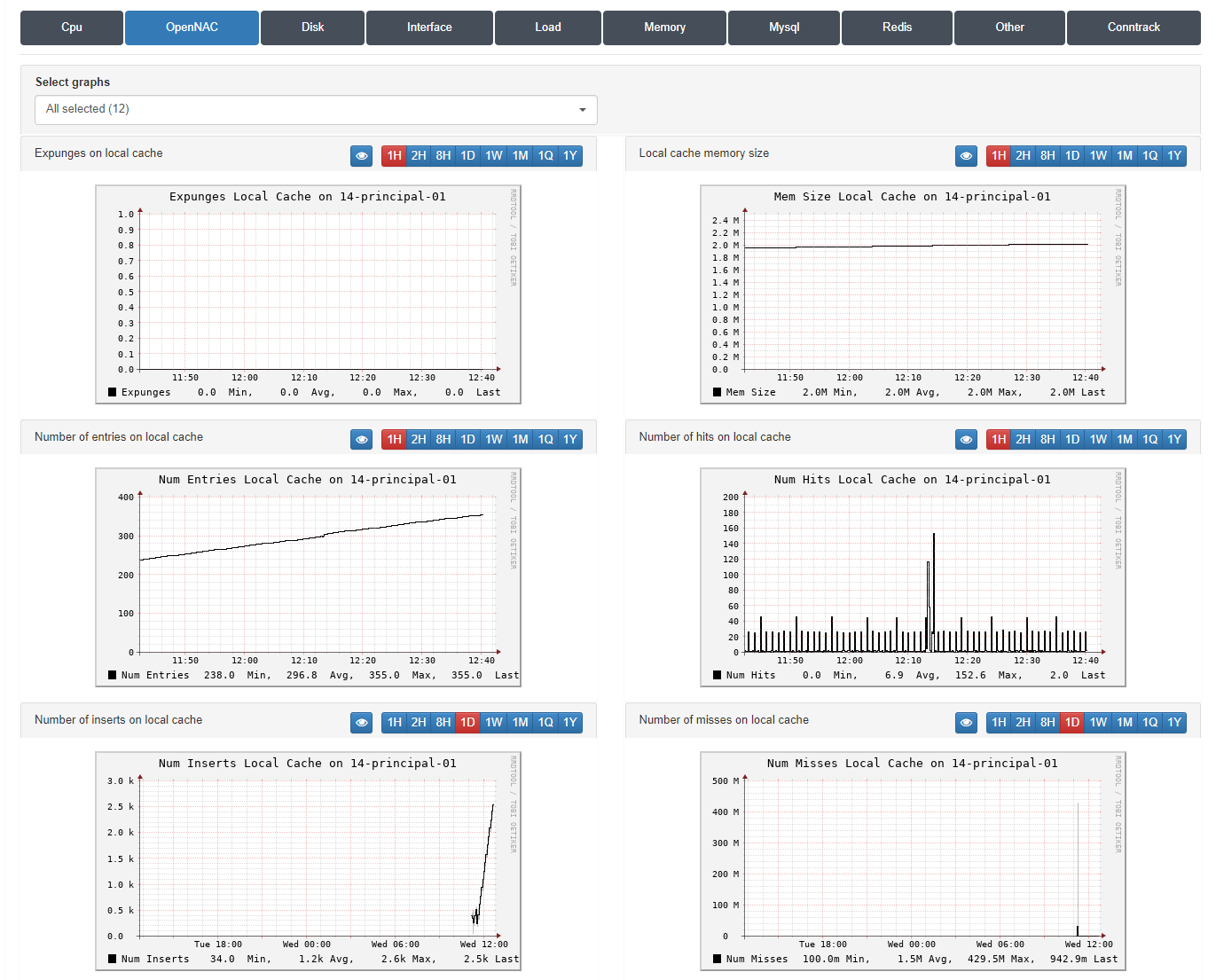
We can classify graphs into:
Cache memory used:
Expunges on local cache: If we see a notable increase in this graph, it means that an element has been purged. This can lead to some other graphs such as the Policy execution time to have considerable increases.
Local cache memory size
Number of entries on local cache
Number of hits on local cache
Number of inserts on local cache: With this graph, we can know, e.g. when cache memory restarts have been carried out, an event that can cause that some other processes at that time take longer than usual. But as mentioned before, the important thing is to be able to observe that, despite these sudden changes, the trend has been as expected.
Number of misses on local cache
Number of slots on local cache
Policy hits, policy execution time:
Policy: gives us information about the number of policies or executions of these that are taking place. We can see that in this graph we have two values, the Endyel Ini, which should normally look the same, since this indicates that all those that start also finish. If there is an imbalance, it would indicate that some policy has remained an unfinished process. With this graph, we can also know on what days or at what times we have more or less load of policy executions.
Policy execution time: tells us how long the policy takes to execute. In this graph, we can see a gray value, which is the actual execution time, and in black the average value of this.
Workers:
Worker queues: In this graph we can find the number of queues available, the pending queues and those that are being executed at the moment respectively. We will have to watch that the red and purple lines (pending and running queues) do not get too close to the total number of available queues. If we occupy all the queues we could find that our system cannot process more requests.
SNMP: on these graphs we can find information about the SNMP requests.
SNMP MAC Change
SNMP MAC Change Worker
PHP_FPM Pools: on these graphs we can find information about the PHP_FPM Pools Status.
PHP_FPM poleval processes: This graph indicates the number of the active, idle and total processes of Poleval PHP-FPM pool.
PHP_FPM www processes: This graph indicates the number of the active, idle and total processes of WWW PHP-FPM pool.
3.1.11.3.3. Trending Disk
In this window, we will see information on the latencies of the disks installed on the servers. We can see the information regarding the writing and reading processes of our disk, referenced in green and blue respectively.
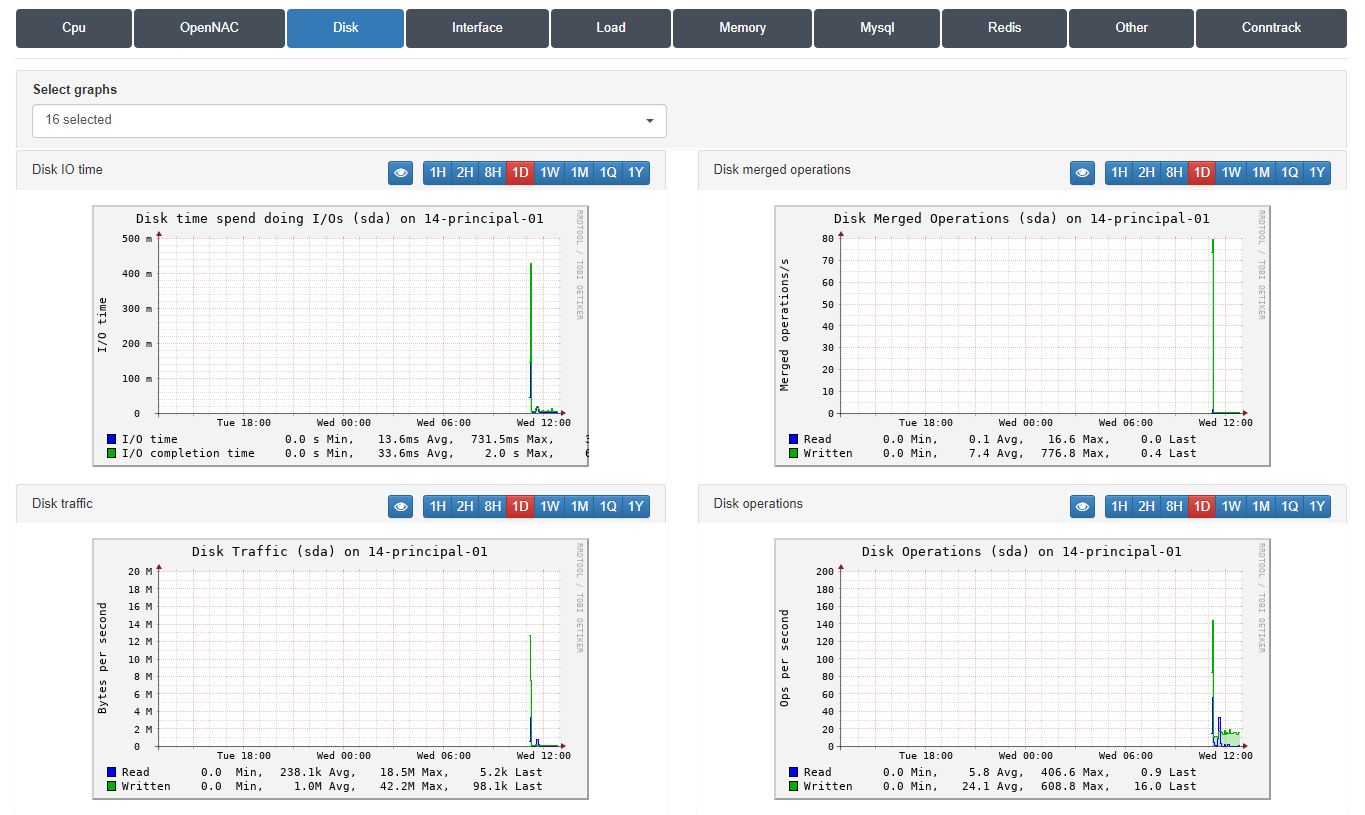
We will see 5 charts for each disk:
Disk IO time: Time spending I/Os.
Disk merged operations: The total of the merged operations that have been carried out on our disk.
Disk traffic: The data traffic that has been written to and read from the disk.
Disk operations: The total operations per second that have been carried out on our disk every second.
Disk time per operation: The average time it took for the disk to perform each operation.
3.1.11.3.4. Trending Interface
In this section is possible to review information for all the interfaces installed on OpenNAC Enterprise Servers. We will be able to see the information referring to the data transmission and reception processes, referenced in green and blue respectively.
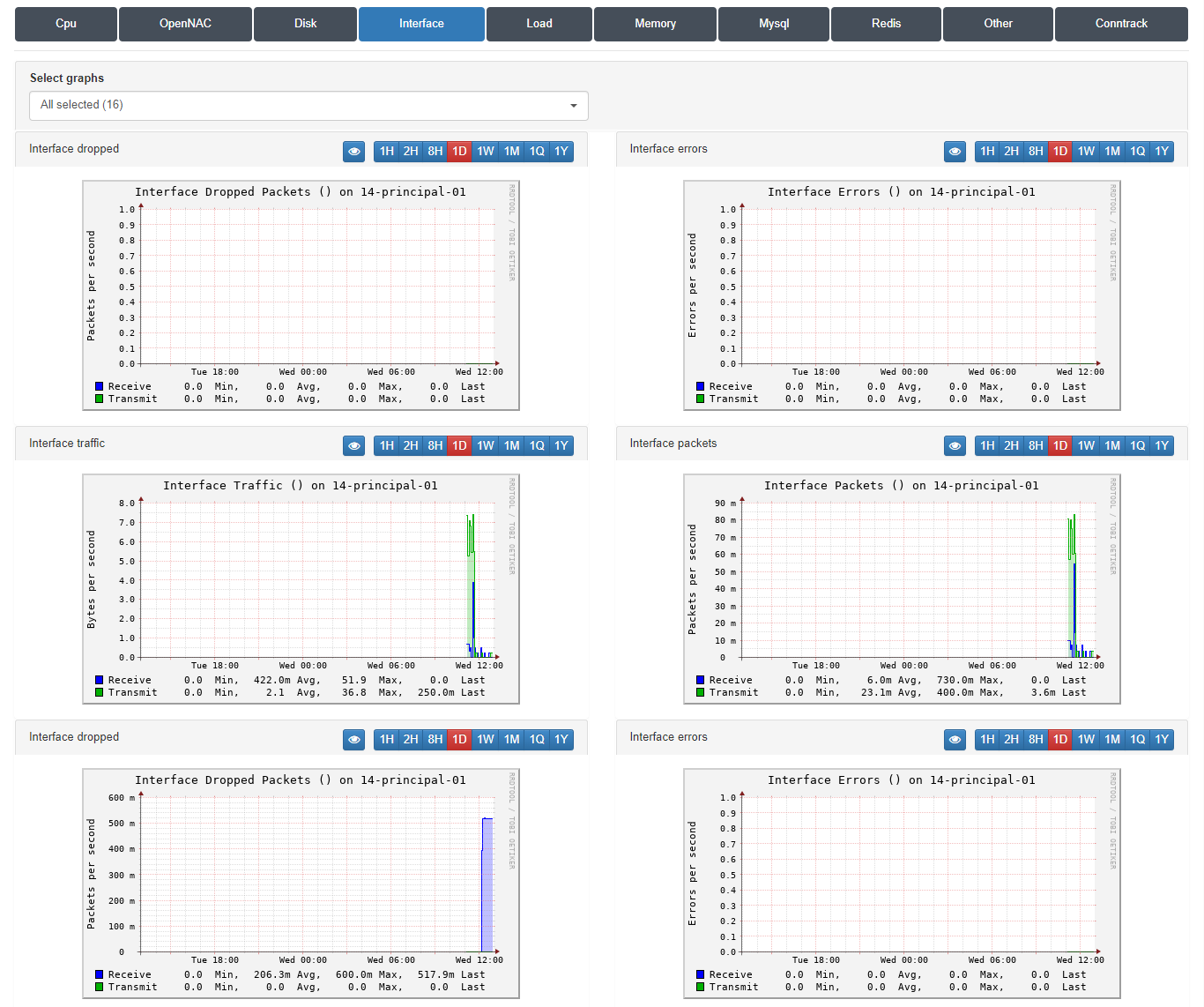
We will see 3 charts for each interface:
Interface Errors: We can see the errors per second that our system has encountered when transmitting or receiving data through said network interface.
Interface packets: The number of packets transmitted and received per second by that network interface.
Interface Traffic: The traffic, indicated in bytes per second, that has been transmitted or received by said network interface.
3.1.11.3.5. Trending Load
To check the system load.
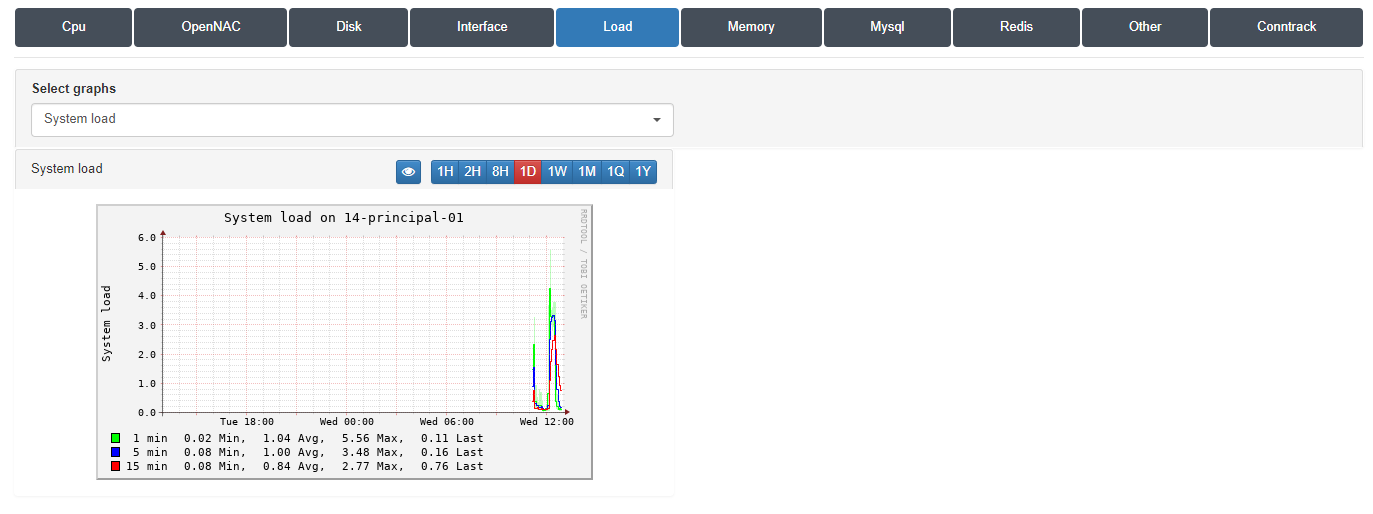
System Load: In this graph, we will be able to see if the system load is greater than 1.0 or if it is less than 1.0. This data indicates that the system is overloaded or insufficiently charged, respectively. We will be able to observe this information regarding the last minute, the last 5 minutes or the last 15 minutes. This information is similar to what we can find by executing the top command through the system CLI.
3.1.11.3.6. Trending Memory
In this section, is possible to review information related to memory load trend.
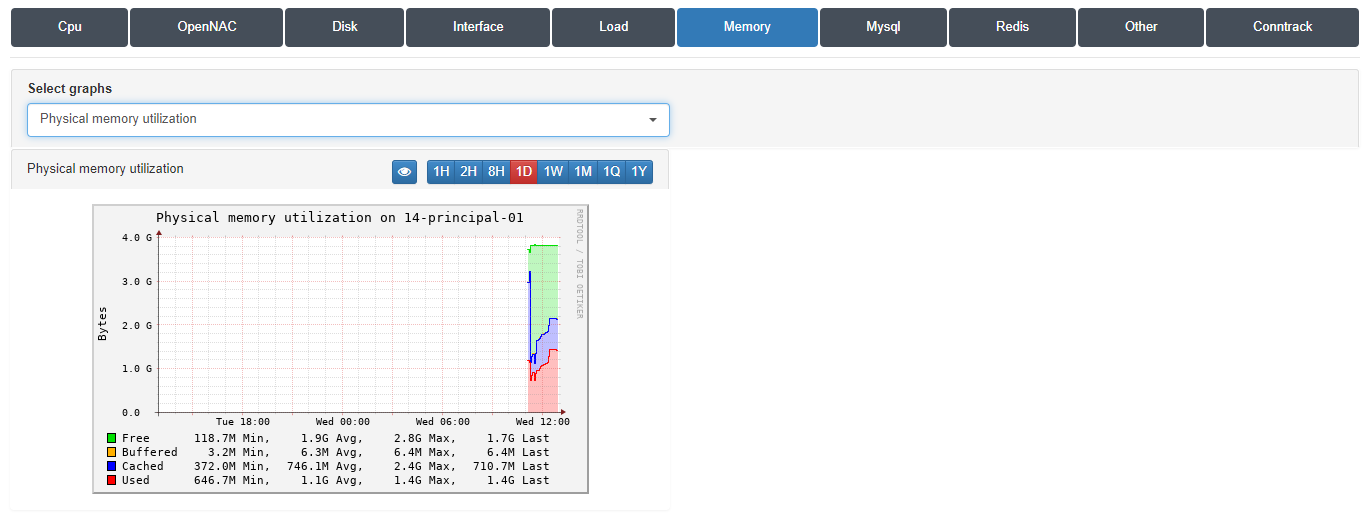
Physical memory utilization: in this graph we can see all of our memory, how much is being used, how much is being used for Cache memory, how much for Buffered memory, and how much is free. The most important thing to observe in this graph is that the memory used, indicated in red, does not occupy the entirety of this graph, since it would indicate that we have filled all the device memory.
3.1.11.3.7. Trending MySQL
AllowsIt allows us to review MySQL trends. There is a total of 12 charts:
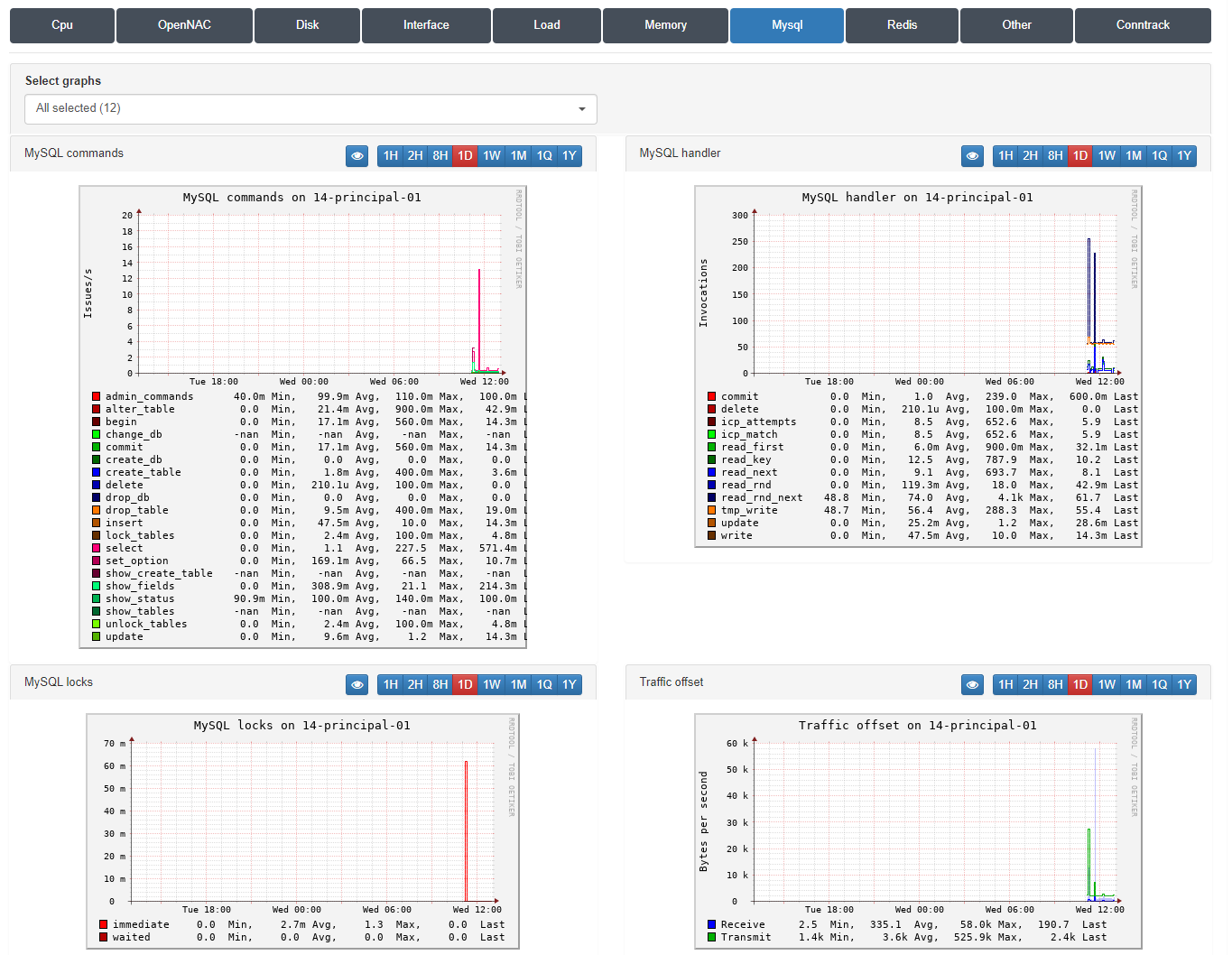
We can classify graphs into:
MySQL commands: The type of commands executed by the different tasks (“issues”) per second (i.e., show master status, flush, grant…)
MYSQL handler: The different invocations of the handler (i.e., commit, delete…)
MySQL locks
Traffic offset: With this graph we can see the information regarding the bytes per second transmitted and received by our database, referenced in green and blue respectively.
MySQL selects
MySQL number of queries that have taken long time
MySQL sorts
MySQL number of merge passes done by sorting algorithm
MySQL sorted rows
MySQL threads processing a query
MySQL total number of threads
MySQL uptime
3.1.11.3.8. Trending Redis
This section allows reviewing Redis trends.
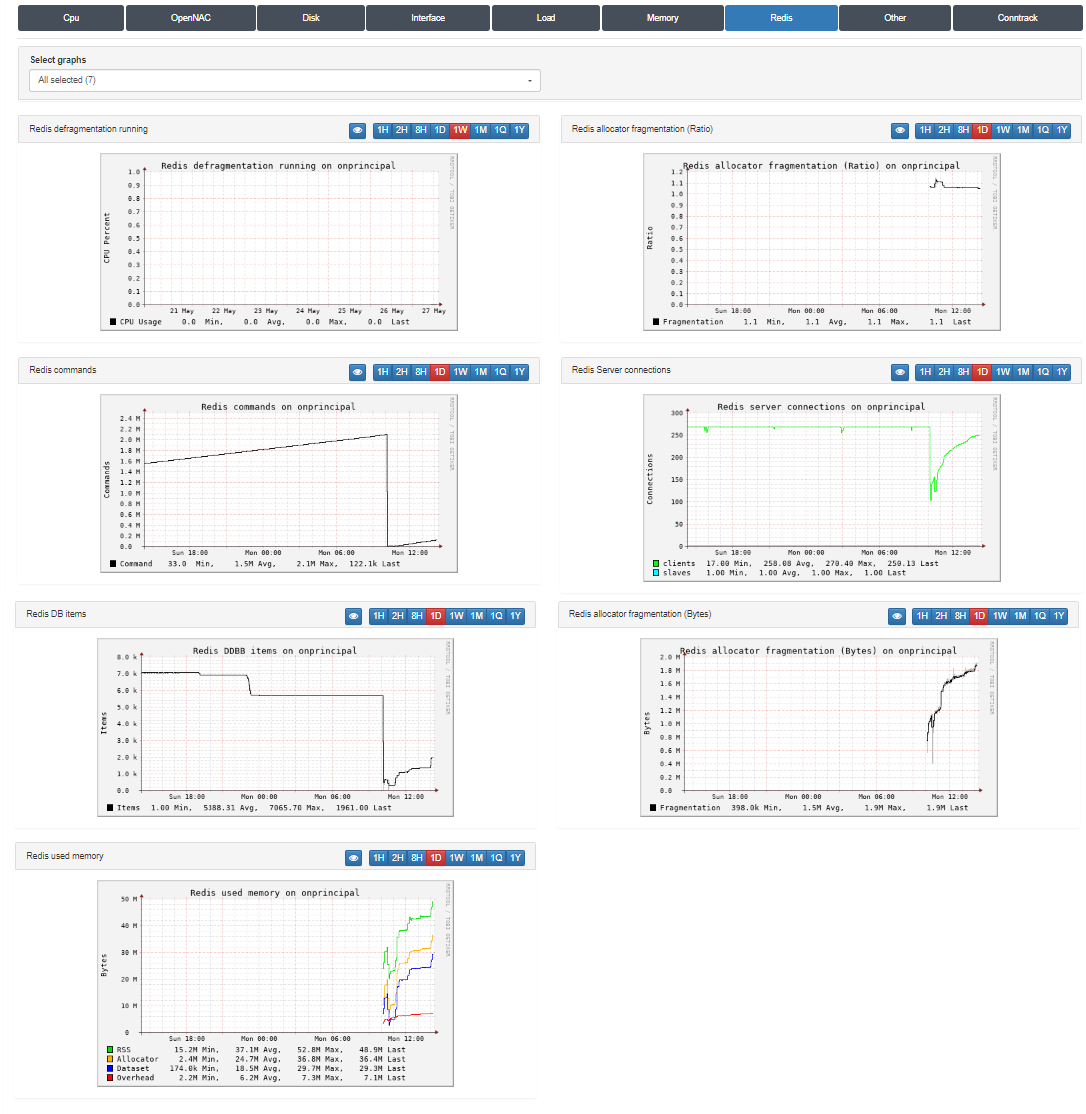
We can see information related to the Redis service:
Redis defragmentation running: CPU usage percentage during Redis defragmentation processes.
Redis allocator fragmentation (Ratio): Ratio of memory fragmentation
Redis commands: The number of redis commands executed.
Redis Server connections: The number of connections to the Redis server from clients and slaves.
Redis DB items: The number of items stored in the Redis database.
Redis allocator fragmentation (Bytes): The amount of fragmented memory in bytes
Redis used memory: Total amount of memory currently used by the Redis server.
3.1.11.3.9. Trending Other
In this window we can see information about our system if it is connected to an Active Directory
As the name of the graph indicates, we can see the errors, the connections, and the response time of the connections with our AD.
Active directory errors
Active directory connections
Active directory response time
3.1.11.3.10. Trending Conntrack
Allows to review Conntrack trends.
Conntrack: the number of conntrack entries on the node.
Percent used: the conntrack percent usage.