2.3.2.2. ON Analytics cluster
In this section, we are going to see how to configure an Elasticsearch cluster. First, we need to understand the following concepts:
Normally, ON Analytics clusters are configured without an Aggregator, so the initial configuration involves configuring the Analytics without an Aggregator.
2.3.2.2.1. Introduction
Cluster
A cluster is a collection of connected nodes identified by its cluster name. Each node in a cluster knows about the other nodes. Each node can accept a client request and forward that to the appropriate node.
It is important to have a resilient cluster, that permits a redundant cluster. If a node is down, the replicas for the primaries in that node are promoted in the nodes that are up, and other replicas are created.
To have a resilient cluster we need the following:
At least three master nodes
At least two nodes of each role
At least one replica per primary shard
Node
A node is a single Elasticsearch instance composed of compute and disk.
It can take multiple roles. The most important roles are:
Master-eligible node: A node that has the master role, which makes it eligible to be elected as the master node, which controls the cluster. This role is in charge with the following actions in the cluster:
Cluster settings
Deleting or creating indices and settings
Adding or removing nodes
Shard allocation to the notes
Data node: A node that has the data role. Data nodes hold data and perform data-related operations such as CRUD, search, and aggregations. A node with the data role can fill any of the specialized data node roles.
Ingest node: A node that has the ingest role. Ingest nodes can apply an ingest pipeline to a document in order to transform and enrich the document before indexing. With a heavy ingest load, it makes sense to use dedicated ingest nodes to not include the ingest role from nodes that have master or data roles.
Small clusters allow some nodes to be assigned as data and master roles at the same time. Instead, large clusters need to have dedicated master nodes and data nodes separated. The dedicated masters don’t need to have the same computing resources as the data nodes.
Index
An index is used to store JSON documents in dedicated data structures corresponding to the data type of fields. An Elasticsearch index is divided into shards.
Shard
Shards are data fragments that compose an Elasticsearch index. There are two types:
Primary shard: Primary shards store the original data and handle read and write operations.
Replica shard: Replicas are copies of primary shards that increase availability and search capacity, distributing the load across cluster nodes. _
Increasing the number of shards can improve load distribution in a cluster environment, while configuring replicas ensures redundancy and fault tolerance.
For example, increasing the number of shards in an environment with 5 analytics nodes can help distribute the load evenly among nodes, ensuring availability.
2.3.2.2.2. Cluster Sizing
The number of nodes is unlimited, it can go through the next range:
1 <= Number of nodes <= no_limit
The characteristics of a large cluster (> 100 nodes) are the following:
More searchable data.
Larger cluster state
Harder for the master to manage
More operational issues
We need to consider the number of shards for our indices. As more primary shards, the consequences are the following:
More parallelism
Faster indexing performance
A bit slower search performance
Our shard should aim for a size between 10 GB and 50 GB. It is recommended 25 GB for search use cases. Larger shards make the cluster less likely to recover from failure (harder to move when a node is going under maintenance).
We also should aim for 20 shards or fewer per GB of heap memory. For example, a node with 30GB of heap memory should have at most 600 shards.
To calculate the number of shards for our indices we can use the following formula:
Number of shards = (index_data + data_to_grow) x (1 + 10% indexing overhead) / desired_shard_size
To calculate the minimum storage required we can use the following formula:
Minimum number required = (index_data ) x (1 + number_replicas) x 1.45
For a cluster handling complex aggregations, search queries, high throughout and frequent updates, the node config should have 2 vCPUs cores, and 8 GB of memory for every 100 GB of storage.
It is necessary to set the elastic search node JVM heap size to no more than 50% (32 GB max) of the physical memory of the backing node.
For example, let’s assume that we have 150 GB of existing data to be indexed.
Number of shards (starting from scratch or no growth)= (150+0) x (1.10) / 25 =~ 7 shards
Number of shards (with 100% growth in a year)= (150+150) x (1.10) / 25 =~ 13 shards
Going with the minimum 3 nodes (master + data). Assuming we would have 1 replica per shard.
Minimum number required = 150 x (1 + 1) x 1.45 = 435 GB of total disk space
Compute and Memory = 435 x (2 vCPUs and 8 GB memory) / 100 = 9 vCPUs and 34.8 GB of memory.
In conclusion, we are going to need 3 nodes each having 3vCPUs, 12 GB of memory, and 150 GB of disk storage. With 12 GB of memory, you can set the JVM heap size to 6 GB (max 120 shards per node, 360 shards in total).
2.3.2.2.3. Cluster architecture
Before seeing different examples of the elastic cluster, we need to know that to not lose data, the minimum number of nodes required are three. That is why two analytics should not be deployed in clients.
The cluster architecture will depend on the number of analytics we want to have on our cluster, if we need or no high availability (HA), and the number of zones we are going to have. The zones are used to define groups of nodes, which can fail all together. Example, imagine you have two data centers, if a data center goes down, you want the other data center to have at least one copy of each shard. With the zones, you can achieve this.
In the following table, we can see the main characteristics of a cluster depending on the number of analytics.
Analytics |
When? |
HA |
Zones |
Replicas |
Shards |
|---|---|---|---|---|---|
1 |
Client that does not need HA |
No |
No zones |
0 |
1 |
2 |
DO NOT USE |
No |
No zones |
0 |
C1 && C2 |
3 |
Clients with just one sites |
Yes |
No zones |
1 |
C1 && C2 |
4 |
Clients with two sites |
Yes |
2 zones |
1 |
C1 && C2 |
5 |
Clients with two sites |
Yes |
2 zones |
1 |
C1 && C2 |
6 |
Clients with two sites or three |
Yes |
2 or 3 zones |
1 or 2 |
C1 && C2 |
… |
More than two sites |
Yes |
corresponding to sites |
replicas = sites |
C1 && C2 |
Note
The number of replicas can be adjusted to clients preferences.
Shards conditions:
C1 = DS * NA - (INDX1 + INDX2 + INDX3 …) > 0
C2 = MAX(INDX{N}) / NS < DS
Where:
DS= Disk space for one node
NS= Number of shards
NA= Number of analytics
INDX{N}= Elastic indexes size
C{N} = Conditions
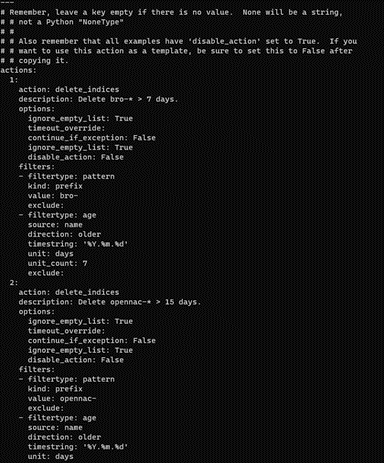
Given the above conditions, we need to adjust the onanalytics curator to prevent the sum of the index sizes from exceeding 85% of the disk space. If this happens, the indexes will enter the read_only state and no information will be ingested into Elasticsearch until the following script located in onanalytics is executed:
/usr/share/opennac/analytics/scripts/read_only.sh
To adjust the index curator, we need to change the days they will be remaining on the disk. To do that, it is necessary to change the following file:
/etc/elastCurator/action.yaml
2.3.2.2.3.1. One ON Analytics
In this case, we only have one Elasticsearch node, so all the information will be ingested in it.

* mdi = master, data and ingest roles
If the onanalytics fall, data will be lost because it would not be ingested.
This kind of architecture does not follow the cluster configuration. The basic configuration should be valid.
Note
Remember to perform the basic configuration before proceeding.
We only need to correctly configure the following parameter.
vi /etc/elasticsearch/elasticsearch.yml
Put the onanalytics IP.
cluster.initial_master_nodes: ["10.10.36.175"]
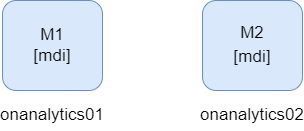
2.3.2.2.3.2. Two ON Analytics
2 nodes 1 replica
Warning
Do not use it on clients.
In this case we can find a cluster with two nodes. The two nodes have data, master and ingest roles. What is necessary in these cases, is to configure one replica to always have a backup shard.
* mdi = master, data and ingest roles
It is not recommended to have only two nodes. Imagine that onanalytics01 is the master elected. If onanalytics02 falls, the shards would be promoted, and the cluster will work correctly without data loss. But, if the node that falls is the master elected, in this case onanalytics01, the cluster will fall because the onanalytics02 would not have any other active master to do a master election. In this second case, the data ingested when the cluster is down, will be lost.
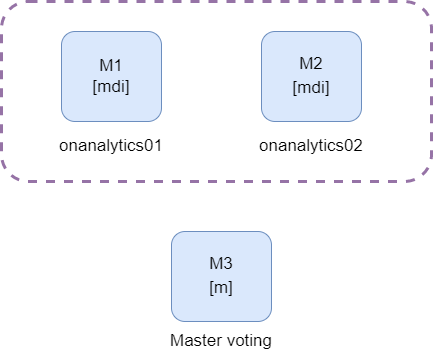
2 nodes 1 replica with a tiebreaker
Warning
If it is possible, use example 3.
In this case we can find the same scenario as in the Example 1. The difference is that we have a master voting that will help us keep the cluster up when a node fails. This will avoid data loss.
* mdi = master, data and ingest roles
2.3.2.2.3.3. Three ON Analytics
In this case, we can find a cluster with three nodes. The three nodes have data, master and ingest roles. What is necessary in these cases, is to configure one replica to always have a backup shard.
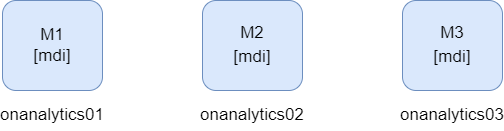
* mdi = master, data and ingest roles
In this case, if one node falls, there would be two master up, so the data will not be lost and the cluster would not fall down.
2.3.2.2.3.4. Four ON Analytics
The minimum number of analytics to have a multizone cluster is 4. In this case we can find two zones with two master nodes each.
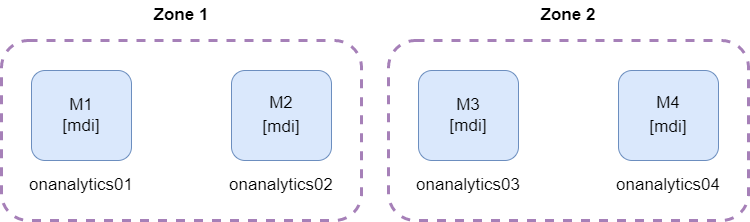
* mdi = master, data and ingest roles
If one of the zones fall down, we will have the other zone with two masters, so it will be possible to do the master election and the cluster will continue up.
2.3.2.2.3.5. Five ON Analytics
In this case, we can find two zones with two masters each, and one data node in one of the zones. One zone will have more disk space than the other.
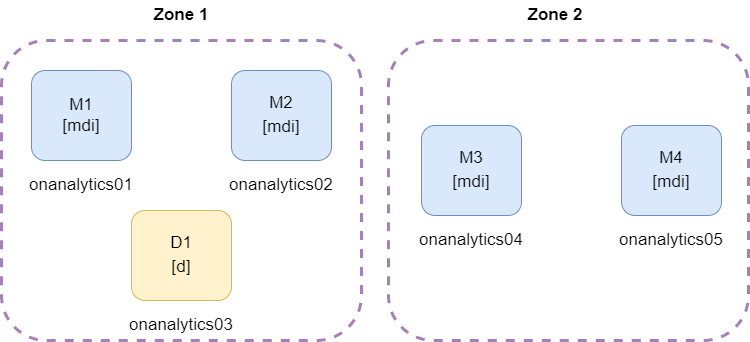
* mdi = master, data and ingest roles
The necessary disk space must be considered, because if the zone with three nodes falls, the zone with two nodes must have enough capacity to store all the information.
2.3.2.2.3.6. Six ON Analytics
2 zones with 3 nodes
In this example, we can see two different zones. It is recommended to separate the elastic nodes in zones when they are connected to different network devices. When one device of the zone gets down, it is possible that all the nodes for that zone are offline.
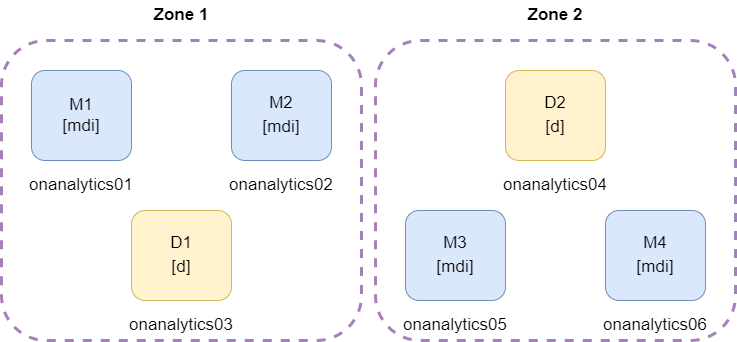
* mdi = master, data and ingest roles
It is necessary to have two masters for every zone because if one zone falls, the other zone conserve two master nodes and the cluster continue up.
2 zones with 3 nodes and 1 voting master
In this example, every zone has one master, and there is a third node, that has another master node. This third zone helps to avoid cluster failure when one zone comes down, because the cluster conserve two active masters.
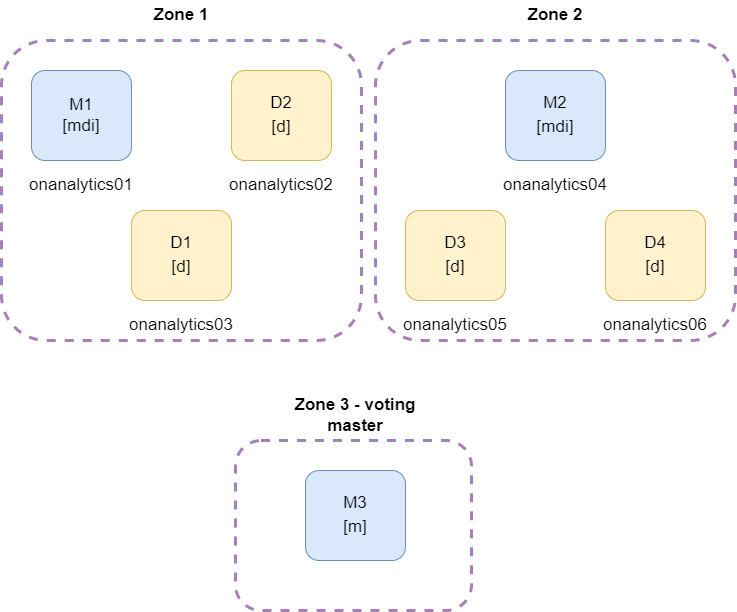
* mdi = master, data and ingest roles
An example of the shards distribution with one replica and two zones can be something similar to the following:
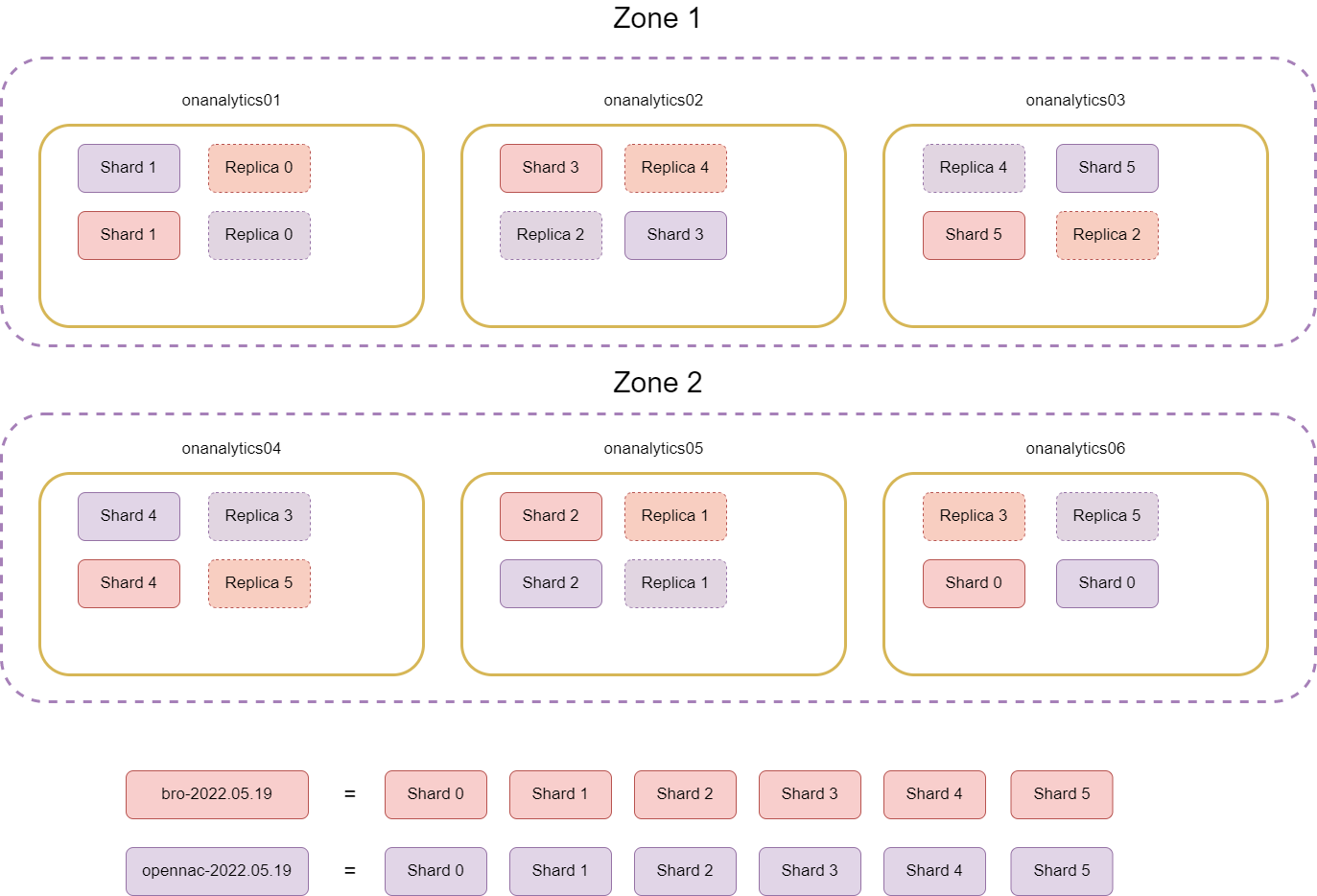
2.3.2.2.3.7. More than six ON Analytics
If we have more than 6 analytics, it is necessary to create the zones corresponding to the number of sites of the client. Then, we need to distribute two master nodes to each zone. The nodes remaining will be data nodes equitably distributed among the different zones.
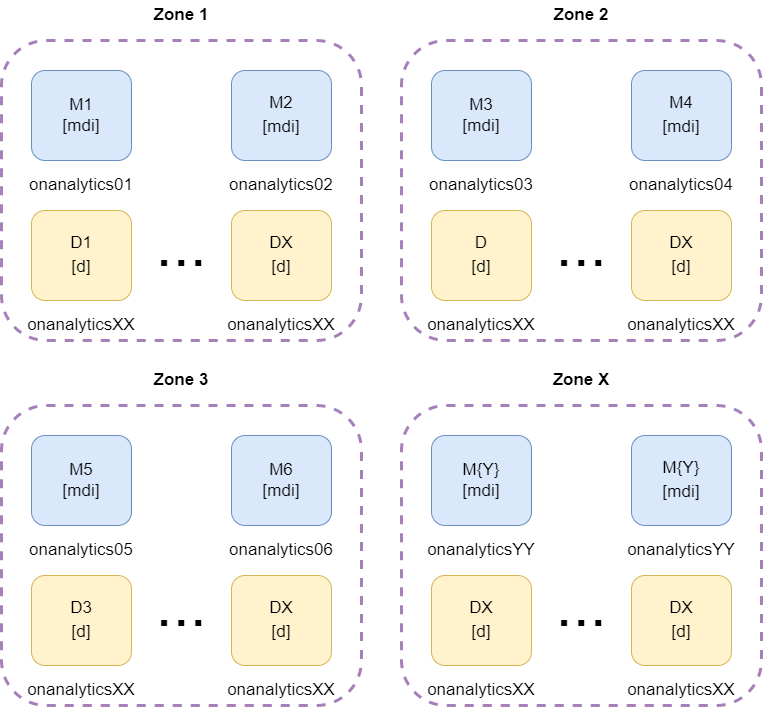
* mdi = master, data and ingest roles
2.3.2.2.4. Iptables configuration
It is necessary the configuration of the iptables.
First of all, we need to copy the analytics iptables template to the iptables file:
yes | cp /usr/share/opennac/analytics/iptables_analytics /etc/sysconfig/iptables
To have the analytics iptables correctly we need to substitute the node variables in of the following files:
vi /etc/sysconfig/iptables
# sample configuration for iptables service
# you can edit this manually or use system-config-firewall
# please do not ask us to add additional ports/services to this default configuration
*filter
:INPUT ACCEPT [0:0]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [0:0]
-A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
-A INPUT -p icmp -j ACCEPT
-A INPUT -i lo -j ACCEPT
# SNMP rule would be enabled only from openNAC Core IPs
#-A INPUT -s <oncoreXX_ip> -p udp -m state --state NEW -m udp --dport 161 -j ACCEPT
# SSH port
-A INPUT -p tcp -m state --state NEW -m tcp --dport 22 -j ACCEPT
# ANALYTICS ports
## KIBANA
#-A INPUT -s <oncoreXX_ip> -p tcp -m state --state NEW -m tcp --dport 5601 -j ACCEPT
## ELASTICSEARCH
#-A INPUT -s <onaggregatorXX_ip> -p tcp -m state --state NEW -m tcp --dport 9200 -j ACCEPT
#-A INPUT -s <oncoreXX_ip> -p tcp -m state --state NEW -m tcp --dport 9200 -j ACCEPT
#### CLUSTER
#-A INPUT -s <onanalyticsXX_cluster_ip> -p tcp -m state --state NEW -m tcp --dport 9300 -j ACCEPT
-A INPUT -j REJECT --reject-with icmp-host-prohibited
-A FORWARD -j REJECT --reject-with icmp-host-prohibited
COMMIT
Finally, restart the iptables service:
systemctl restart iptables
2.3.2.2.5. Cluster Configuration
Note
Remember to perform the Basic Configuration before proceeding.
Before creating a cluster, we need to delete all the Elastic data. If we have important info in our Elastic, we will need to export the data before deleting it and import it when the cluster is up again. If we want to add a node to the current cluster, we also need to delete the data of the new node.
systemctl stop elasticsearch
rm -rf /var/lib/elasticsearch/nodes
2.3.2.2.5.1. Master
First, we need to edit the elasticsearch configuration file:
vi /etc/elasticsearch/elasticsearch.yml
For a Master node we need to edit the following lines:
The cluster name. It needs to be the same on all the analytics in the cluster.
cluster.name: <CLUSTER_NAME>
The node name.
node.name: <NODE_NAME>
The zone configuration if it is necessary. All the nodes in the same zone need to have the same zone ID.
node.attr.rack: <ZONE_ID>
cluster.routing.allocation.awareness.attributes: rack
The discover seed hosts. We need to add the master’s IPs, excluding its own IP.
discovery.seed_hosts: ["<MASTER2_IP>","<MASTER3_IP>"]
The cluster initial master nodes. We need to add the master’s node names.
cluster.initial_master_nodes: ["<MASTER1_NODE_NAME>","<MASTER2_NODE_NAME>","<MASTER3_NODE_NAME>"]
We need to add the following lines for select master role, data role, and ingestion role.
node.master: true
node.data: true
node.ingest: true
Save the file and restart the elasticsearch.
systemctl restart elasticsearch
2.3.2.2.5.2. Data
First, we need to edit the elasticsearch configuration file:
vi /etc/elasticsearch/elasticsearch.yml
For a Data node, we need to edit the following lines:
The cluster name. It needs to be the same on all the analytics in the cluster.
cluster.name: <CLUSTER_NAME>
The node name.
node.name: <NODE_NAME>
The zone configuration if it is necessary. All the nodes in the same zone need to have the same zone ID.
node.attr.rack: <ZONE_ID>
cluster.routing.allocation.awareness.attributes: rack
The discover seed hosts that provide a list of the addresses of the master-eligible nodes in the cluster. We need to add the master’s Ips or the name resolution in /etc/hosts, excluding its own IP.
discovery.seed_hosts: ["<MASTER2_IP>","<MASTER3_IP>"]
The cluster’s initial master nodes, that sets the initial set of master-eligible nodes in a new cluster. We need to add the masters node names.
cluster.initial_master_nodes: ["<MASTER1_NODE_NAME>","<MASTER2_NODE_NAME>","<MASTER3_NODE_NAME >"]
We need to add the following lines for select master role, data role, and ingestion role.
node.master: false
node.data: true
node.ingest: false
Save the file and restart the Elasticsearch service.
systemctl restart elasticsearch
To see that all the roles and nodes are configured properly we can execute the next command on any node in the cluster:
curl -XGET localhost:9200/_cat/nodes?v=true&pretty=true
We will see something like the following:

2.3.2.2.5.2.1. Number of shards and replicas
To add the number of shards and replicas, we need to go to a Master cli and execute the following curl:
curl -XPUT localhost:9200/_template/index_defaults -H "Content-Type: application/json" -d '
{
"template": "*",
"settings": {
"number_of_shards": <NUMBER_OF_SHARDS>,
"number_of_replicas": <NUMBER_OF_REPLICAS>
}
}'
All the indexes that will be created in the future will be divided in the number of shards entered, and every shard will have the number of replicas entered.
If an index already exists, the number of shards will not be modified, but we can reindex it to get the number of shards we want. To reindex an index, we need to execute the following steps:
Copy the index into a new index. It will create a new index with the new shards and replica number.
curl -X POST "localhost:9200/_reindex" -H 'Content-Type: application/json' -d '
{
"source": {
"index": "<INDEX_NAME>"
},
"dest": {
"index": "new_index"
}
}'
Remove the old index.
curl -XDELETE http://localhost:9200/<INDEX_NAME>
Copy the new index into the index we are reindexing:
curl -X POST "localhost:9200/_reindex" -H 'Content-Type: application/json' -d '
{
"source": {
"index": "new_index"
},
"dest": {
"index": "<INDEX_NAME>"
}
}'
Delete the auxiliary index created:
curl -XDELETE http://localhost:9200/new_index
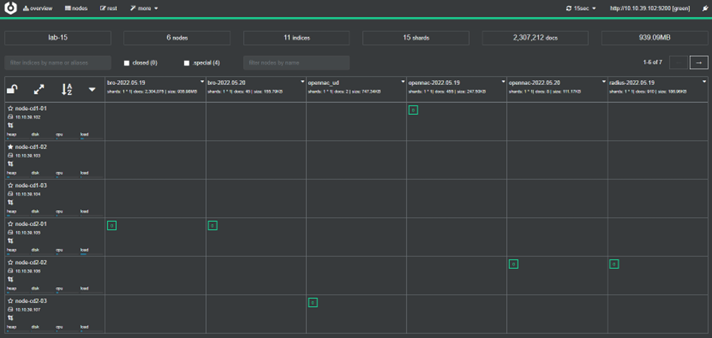
With the open source Cerebro (Annex A - Install Cerebro), we can see that the new changes have been applied:
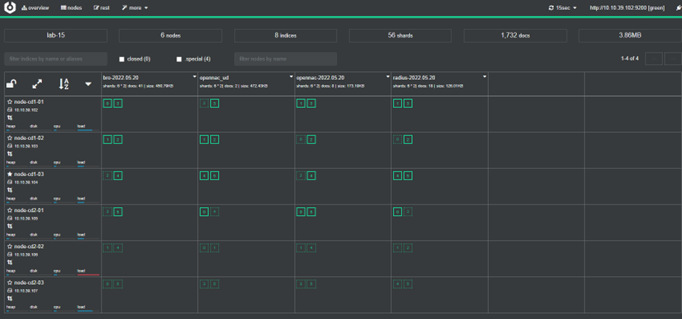
2.3.2.2.5.3. Elasticsearch networking
There are some parameters that can be useful in the elasticsearch.yml file:
vi /etc/elasticsearch/elasticsearch.yml
By default, Elasticsearch only binds to loopback addresses such as 127.0.0.1 and [::1]. This is sufficient to run a cluster of one or more nodes on a single server for development and testing, but a resilient production cluster must involve nodes on other servers. There are many network settings, but usually, all you need to configure is network.host:
network.host: 192.168.1.10
When you provide a value for network.host, Elasticsearch assumes that you are moving from development mode to production mode, and upgrades a number of system start-up checks from warnings to exceptions. See the differences between development and production modes.
The network.host setting explained in Commonly used network settings is a shortcut that sets the bind host and the publish host at the same time. In advanced used cases, such as when running behind a proxy server, you may need to set these settings to different values:
network.bind_host: This specifies which network interface(s) a node should bind to in order to listen for incoming requests. A node can bind to multiple interfaces, e.g. two network cards, or a site-local address and a local address. Defaults to network.host.
network.publish_host: The publish host is the single interface that the node advertises to other nodes in the cluster, so that those nodes can connect to it. Currently, an Elasticsearch node may be bound to multiple addresses, but only publishes one. If not specified, this defaults to the “best” address from network.host, sorted by IPv4/IPv6 stack preference, then by reachability. If you set a network.host that results in multiple bind addresses yet rely on a specific address for node-to-node communication, you should explicitly set network.publish_host.
When the parameters are changed, save the file and restart the Elasticsearch service.
systemctl restart elasticsearch
2.3.2.2.5.4. Import Data to Elasticsearch
When the Elasticsearch cluster is created and up, we need to add the following templates mappings executing the following curls:
curl -s --noproxy "*" -H 'Content-Type: application/json' -XPUT 'http://localhost:9200/_template/identities' -d@/usr/share/opennac/analytics/elasticsearch/index_template_identities.json
curl -s --noproxy "*" -H 'Content-Type: application/json' -XPUT 'http://localhost:9200/_template/bro' -d@/usr/share/opennac/analytics/elasticsearch/index_template_bro.json
curl -s --noproxy "*" -H 'Content-Type: application/json' -XPUT 'http://localhost:9200/_template/radius' -d@/usr/share/opennac/analytics/elasticsearch/index_template_radius.json
curl -s --noproxy "*" -H 'Content-Type: application/json' -XPUT 'http://localhost:9200/_template/opennac_captive' -d@/usr/share/opennac/analytics/elasticsearch/index_template_opennac_captive.json
curl -s --noproxy "*" -H 'Content-Type: application/json' -XPUT 'http://localhost:9200/_template/opennac' -d@/usr/share/opennac/analytics/elasticsearch/index_template_opennac.json
curl -s --noproxy "*" -H 'Content-Type: application/json' -XPUT 'http://localhost:9200/_template/opennac_macport' -d@/usr/share/opennac/analytics/elasticsearch/index_template_opennac_macport.json
curl -s --noproxy "*" -H 'Content-Type: application/json' -XPUT 'http://localhost:9200/_template/opennac_net_dev' -d@/usr/share/opennac/analytics/elasticsearch/index_template_opennac_nd.json
curl -s --noproxy "*" -H 'Content-Type: application/json' -XPUT 'http://localhost:9200/_template/opennac_nd-' -d@/usr/share/opennac/analytics/elasticsearch/index_template_opennac_nd-.json
curl -s --noproxy "*" -H 'Content-Type: application/json' -XPUT 'http://localhost:9200/_template/opennac_ud' -d@/usr/share/opennac/analytics/elasticsearch/index_template_opennac_ud.json
curl -s --noproxy "*" -H 'Content-Type: application/json' -XPUT 'http://localhost:9200/_template/misc' -d@/usr/share/opennac/analytics/elasticsearch/index_template_misc.json
curl -s --noproxy "*" -H 'Content-Type: application/json' -XPUT 'http://localhost:9200/_template/external_syslog' -d@/usr/share/opennac/analytics/elasticsearch/index_template_external_syslog.json
curl -s --noproxy "*" -H 'Content-Type: application/json' -XPUT 'http://localhost:9200/_template/third_party_vpn' -d@/usr/share/opennac/analytics/elasticsearch/index_template_third_party_vpn.json
Then, we need to import all the Kibana customized data to the .kibana index in Elasticsearch:
bash /usr/share/opennac/analytics/scripts/elk8_update.sh -o update
2.3.2.2.6. Annex A - Install Cerebro
Cerebro is an open source (MIT License) elasticsearch web admin tool built using Scala, Play Framework, AngularJS and Bootstrap.
https://github.com/lmenezes/cerebro
Is it important to install Cerebro in a server that has access to the elasticsearch cluster.
To install Cerebro, we need to download the last release from:
https://github.com/lmenezes/cerebro/releases
In our case, we are going to download the next release:
wget https://github.com/lmenezes/cerebro/releases/download/v0.9.4/cerebro-0.9.4-1.noarch.rpm
It is necessary to install it:
rpm -i cerebro-0.9.4-1.noarch.rpm
And then we need to execute it:
/bin/cerebro
The default port for Cerebro is 9000. If we want to execute Cerebro in another port we can use the following command:
bin/cerebro -Dhttp.port=<NEW_PORT>
When Cerebro is running we can access from a browser with the following URL:
http://<SERVER_IP>:<CEREBRO_PORT>
We will see the following:
Entering an elastic server IP, we will see all the information that Cerebro give us about the elastic cluster. For example:
http://<ELASTIC_SERVER_IP>:9200